前言
从早期的 ButterKnife,Dagger2,EventBus 到如今的 ARouter, WMRouter ,SugarAdapter(也许还有其他的,平时关注较多的就是这些),借助注解处理器 APT,各路神仙开发了许多有用的工具、框架,解放了 Android 开发者的双手,让我们少写了很多冗余的代码,也使得组件化这样的开发思路可以大行其道。
试想,如果没有 ButterKnife 这样的神器,那么现在每一个 Android 开发者估计下辈子都会记得 findViewById 这个方法,真是能让人写的吐血的一个方法。(当然,现在上了 Kotlin 的车,这都不是问题了)。
你能想象在 EventBus 尚未诞生的时候,我曾经为了把一个方法的值从某个 RecyclerView 的 Adapter 传递到另一个 Activity 的 Fragment 里写了多少层的回调吗?你能想象一个 Activity(Fragment) 的 onActivityResult 有 100 多行的条件判断(仅仅是返回值按 requestCode 取值,不包括任何业务逻辑),去获取其他页面的各种返回值是多么的让人绝望吗?甚至有些时候还要考虑被启动的 Activity 在特定的启动模式下,onActivityResult 方法回调异常的情况,更是出现了无法实现业务需求的窘境 😢
在组件化开发的早期,类依赖是最最痛苦的问题,两个从业务上已经剥离的组件,却因为要实现页面跳转(简单来说就是依赖 Activity 或 Fragment 类)而不得不产生依赖。路由框架在 Android 中的应用,完美的解决了这个问题。
而这些框架,都用到了注解处理器这项技术,因此这里就来学些一下什么是注解处理器,以及注解处理器可以做什么。
注解处理器 APT 是什么,能做什么 ?
APT 处理哪种类型的注解
注解处理器,顾名思义就是用于处理注解的工具。
在理解 Android 中的注解与反射 一文中我们已知,Java 代码在运行时会通过反射的方式处理 注解作用范围@Retention 为 RetentionPolicy.RUNTIME 的注解。而今天的主角 APT 则负责处理注解作用范围 @Retention 为 RetentionPolicy.CLASS 的注解。
APT 的作用
APT(Annotation Processing Tool)即注解处理器,是一种处理注解的工具,确切的说它是 javac 的一个工具,它用来在编译时扫描和处理注解。注解处理器以 Java 代码(或者编译过的字节码)作为输入,生成.java 文件作为输出。简单来说就是在编译期,通过注解生成.java 文件。
注解处理器小试牛刀
注解处理器工程的创建
注解处理器的使用很简单,网上已经有很多的例子和实现,可以参考Android 如何编写基于编译时注解的项目 ,轻松打造一个自己的注解框架 这两篇文章搭建一个合适的注解处理器框架。为了后续描述方便,这里也简单写了一个 Demo ,代码已同步到Github APT-Lite 仓库,可以参考。
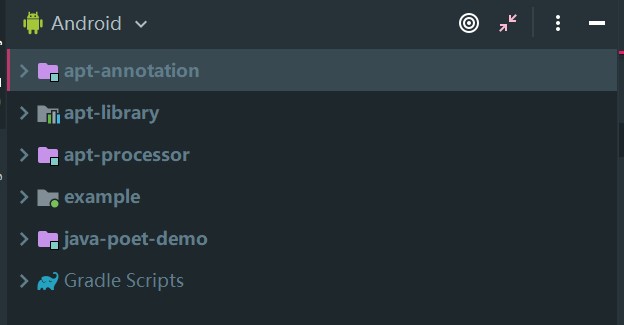
一般来说按照上图
- apt-annotation (java module) 定义所有需要用到的注解(require)
- apt-processor (java module) 解析注解并生成 java 代码 (require)
- apt-libray (android module) 定义对外暴露的 API 接口 (option)
- example (android module) demo (option)
这样定义就足够了。就注解处理器实际要实现的业务功能,apt-library 可能需要定义在其他组件中,甚至某些注解处理要实现的功能,如果和业务有强绑定,这个 api 甚至都可能不存在,example(或 app) 作为验证(演示)注解功能的 module 是可以忽略的,因此注解处理器框架实际上就是一个纯 Java 项目。
关于在工程中这些模块的 build.gradle 中相互依赖关系及依赖哪些库,这里就不展开了,毕竟很简单,具体结合上面的两篇文章可以很轻松的完成配置。
小目标(BindView & BindString)
简单起见,我们也从模仿 ButterKnife 开始,简单定义两个注解,BindView 和 BindString ,代码运行后可以实现 变量和 View 的自动绑定。
1 | public class MainActivity extends AppCompatActivity { |
上述代码,在运行期可以正确的找的 id 为 content 和 name 的 TextView 并分别赋值为 “Hello APT” 和 “APT Success”
apt-annotaion
定义我们需要用到两个注解
- BindView
1 |
|
- BindString
1 |
|
apt-processor
apt processor 的实现,是 APT 最核心的内容。但是要做的事情也很简单。就是继承 AbstractProcessor 类,并实现它的四个方法
- init
- getSupportedSourceVersion (可以用注解代替)
- getSupportedAnnotationTypes (可以用注解代替)
- process
这四个方法的定义及功能,就不展开说了,通过参考资料中的内容,甚至其命名我们就可以知道这几个方法的作用是啥了。
为了方便,我们可以先简单的抽取一层 BaseProcessor。对于一些常用的初始化一些常用的成员变量。
1 | public abstract class BaseProcessor extends AbstractProcessor { |
BindViewProcessor
下面就通过 BindViewProcessor 看看如何实现我们的目标。
- 首先定义要支持的注解类型
1 |
|
- process 核心逻辑的处理
1 |
|
ps: 可能是受到鸿洋老师这篇 Android 如何编写基于编译时注解的项目的影响,现在看到网上注解处理器的文章,都会新建 Proxy 通过代理模式来处理生成代码的核心逻辑,o(╥﹏╥)o。 这里为了方便也是用代理类处理。
- assembleAnnotations() 对注解进行完全的处理
1 | /** |
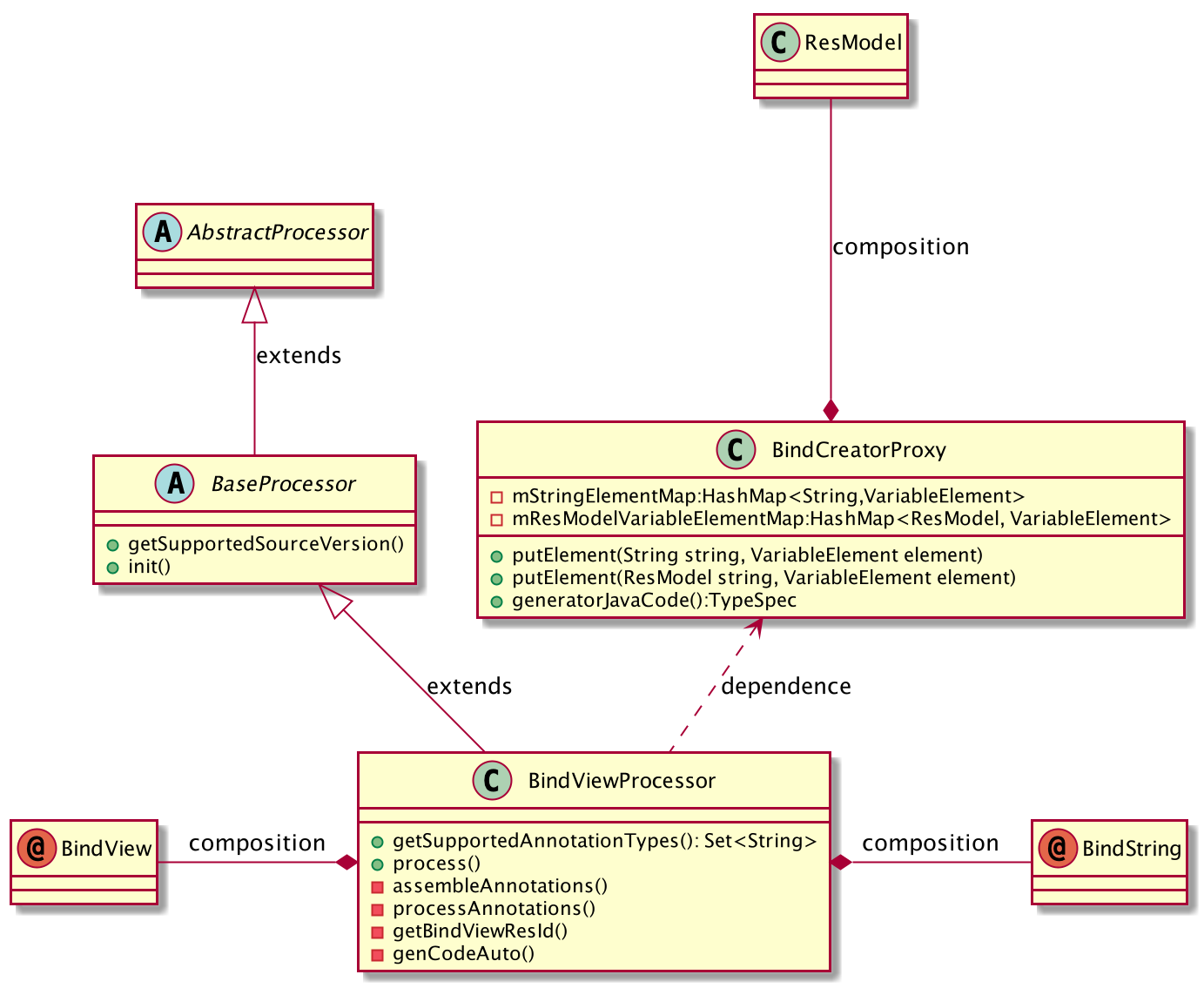
为了便于理解上面的代码,可以看一下整个 apt-processor 的 UML 类图
总的来说,mProxyProMap 是以注解所在的类名为 key ,BindCreatorProxy 为值的一个 map。这样做为了方便以 @BindView,@BindString
注解所在的类为维度,解析注解生成代码。BindCreatorProxy 中的 putElements() 方法会保存注解对应的 value 和 element 的映射表(即一个 HaspMap)。
getBindViewResId()
这里再来简单说一下 getBindViewResId 这个方法,这里其实是借用 RParser为了便于生成更加友好的代码。因为我们通过 R 文件直接获取到的 View 的 id 一般是无意义的一个数字,因此生成的文件一般会是类似
1
target.mName = target.findViewById(2131165246);
这样的代码,理论上来说,这里的 id 是以什么样的形态存在,其实无所谓,但为了更加友好的阅读体验,我们可以再优化一下注解生成器把生成的代码变成这个样子
1
target.mName=target.findViewById(com.engineer.aptlite.R.id.name);
这样的代码更接近我们最终想要看到的样子。
代码生成
mProxyProMap 已经包含所有我们需要信息,接下来就可以根据这个集合生成代码了。在 APT 处理过程中,一般会选择使用 javapoet 来生成代码,这个库提供了很多 api 方法开发者按照面向对象的方式输出一个包含导包,类声明,变量声明,方法定义等各种信息的类文件。当然,你也可以选择使用字符串拼接的方法,按照你希望的格式进行拼接即可。
- genCodeAuto()
1 | private void genCodeAuto() { |
这里遍历所有需要生成的类,分别为他们生成文件,proxyPro.generatorJavaCode() 的具体实现
1 | public TypeSpec generatorJavaCode() { |
这里使用 javapoet 实现,可以看到他的 API 设计命名还是很清晰的,基本上根据方法命名就可以知道需要做什么事情了,这里的实现就很简单了,具体细节就不展开了,可以参考源码
生成的目标代码
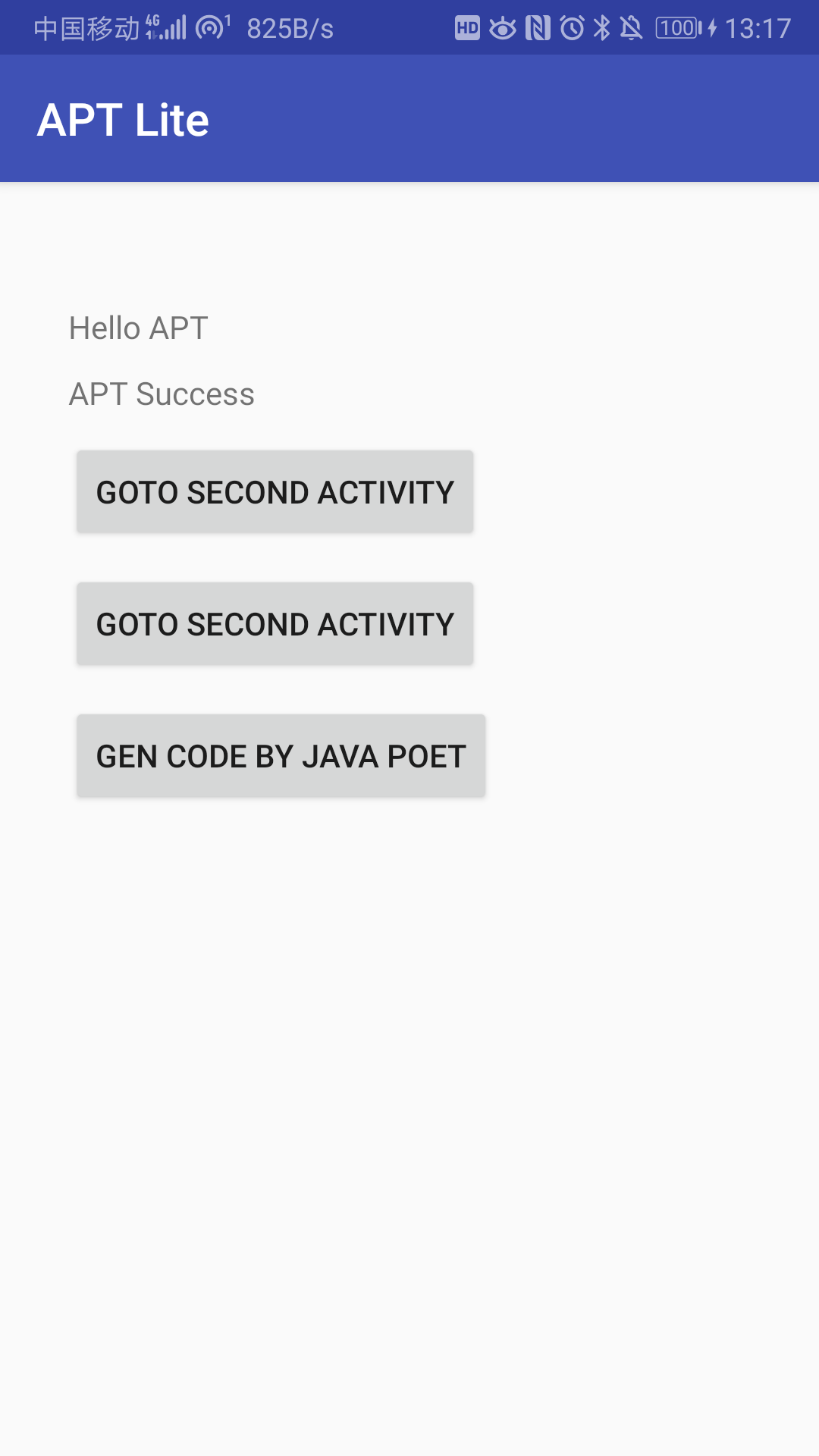
以上面我们制定的目标 MainActivity为例,那么最终在编译期生成的代码就是这个样子:
1 | package com.engineer.aptlite; |
这个文件在一般会在 /app/build/generated/source/apt/debug/packagename/ 目录下。但其实也不用按照目录找,Android Studio 切换到 Android 目录视图下,在 generatedJava 包下即可非常方便的找到
可以看到和我们手写的基本差不多。代码可以正常运行,说明一切都正常,说明编译期生成的代码是有效的。
总结
使用 APT 可以帮助我们在编译期预先完成一些重复性较强,且很有规律的事情,生成一些辅助性的代码,最终在我们编码的时候,可以借助这些辅助类更高效和准确的完成工作。例如 SugarAdapter 通过在编译期生成的文件,解决了 RecyclerView 需要多种类型的 Item 时,Adapter 实现爆炸的问题。有兴趣的同学可以看看用 SugarAdapter 简化复杂列表的实现
注解处理器在 Kotlin 中的使用注意事项
在常规的 java 版本的 Android 项目中,为了引入带有注解处理器的库,一般会最 build.gradle 的 dependencies 闭包中会使用annotationProcessor 来使用注解处理器,比如 glide 的依赖
1 | dependencies { |
在 Kotlin 中需要替换为 kapt 了。具体来说,首先需要添加 kapt 的插件
1 | apply plugin: 'kotlin-kapt' |
然后将所有需要使用 annotationProcessor 的地方替换为 kapt 即可。

